In 2023, Google asked for permission to lock down the open web, was refused – and has now simply released the exact same thing as a product update that no one voted on.
Rick Findlay
In 2023, Google proposed something called “Web Environment Integrity.” The idea was that websites could check whether your browser was running on Google-certified hardware before granting you access. Mozilla opposed this.
Brave stated that it would never release the feature. Vivaldi warned: “Any browser that chooses not to implement this would no longer be considered trustworthy, and any website using this API could reject users of such browsers.”
Google withdrew the proposal within a few months. The public had won.
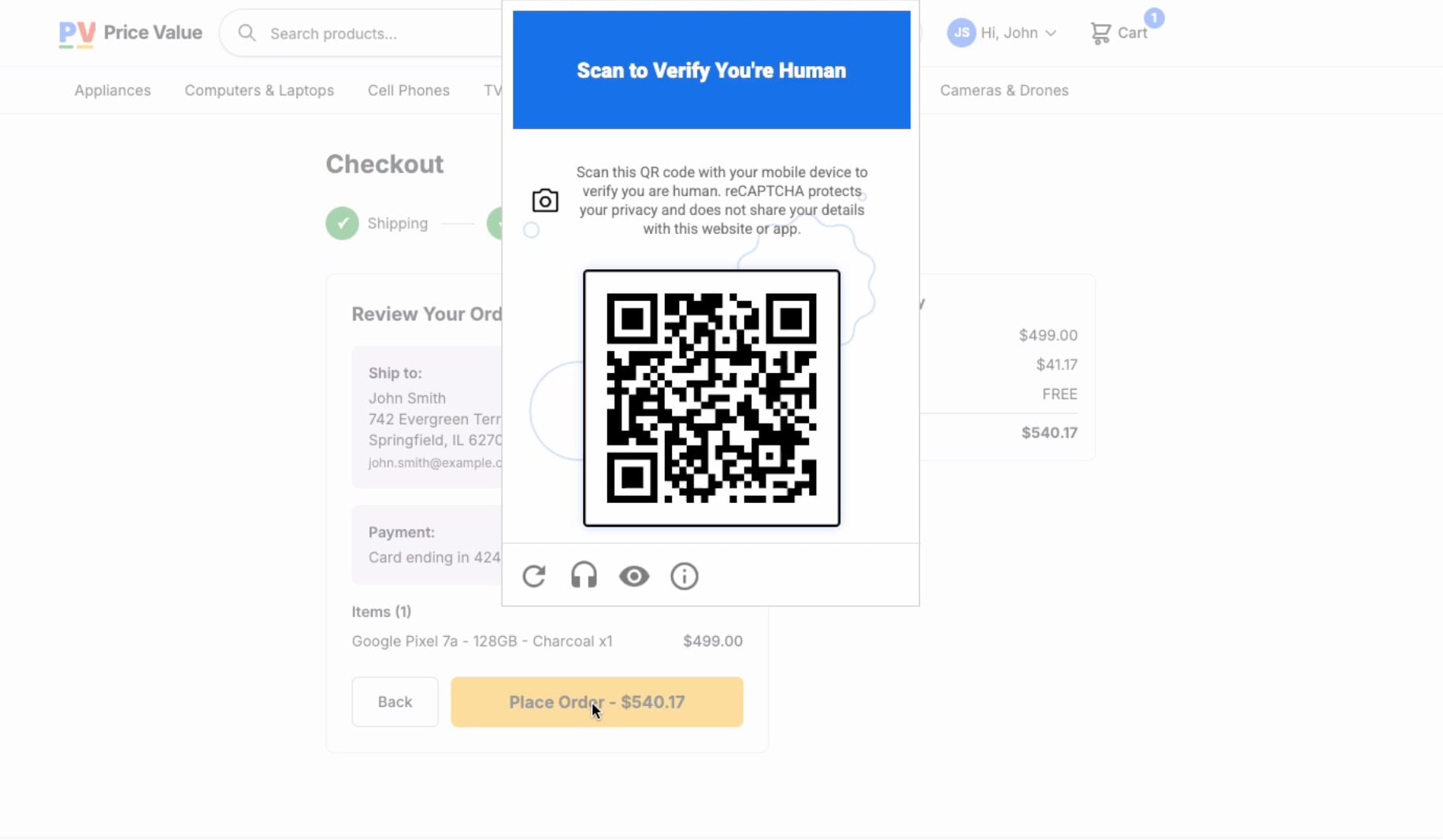
Three years later, however, at Cloud Next ’26, Google announced “Fraud Defense”—marketed as the next evolution of reCAPTCHA. It uses the same Play Integrity API. It requires the same Google-certified hardware and performs the same device attestation. The difference is: this time, Google didn’t ask anyone. There was no standardization process and no public review. The request page simply went live, and Fraud Defense was rolled out across the existing reCAPTCHA installation base of more than 14 million domains.
The standardization process that halted WEI existed for a very specific reason: to prevent a single company from deciding who could use the open web. Google found a workaround. It simply brought the same mechanism to market as a commercial product.
How reCAPTCHA already penalizes you if you’re not a Google customer

The rating has been manipulated for years. reCAPTCHA v3 assigns each visitor a risk score between 0.0 and 1.0. Technology consultants who tested the system found that browsers logged into a Google account consistently received low risk scores, while the same websites accessed via Tor or a VPN were classified as high risk.
Being logged into Google and thus handing over your browser data to Google’s tracking system is considered proof that you are a human. Protecting your privacy, on the other hand, is treated as an indication that you might be a bot.
Anyone who’s ever used a VPN knows this from experience. If you stay logged into your Google account, reCAPTCHA passes you through with a single click or even without any verification at all. But if you log out, switch to Firefox, or activate a tracker blocker, the puzzles begin. They repeat themselves. They get harder. Sometimes they never end.
VPN users experience something even worse because VPN server IP addresses are shared by thousands of people. The behavior of a few users poisons the reputation of the entire address. VPN IPs with a bad reputation trigger CAPTCHA failure rates between 80 and 100 percent – including more difficult puzzles on top of that.
Privacy extensions like uBlock Origin or Privacy Badger can completely disrupt reCAPTCHA scripts. The result is endless loops where verification becomes impossible – no matter how many crosswalks you correctly identify.
The difficulty of reCAPTCHA increases inversely proportional to how much Google knows about you. That’s exactly how the system is designed.
The people this actually affects
Researchers who scanned the entire IPv4 address space found that 1.3 million websites deny connections from known Tor exit nodes. Around 3.67 percent of the top 1,000 websites block Tor users directly at the application level. The researchers concluded that Tor users are “effectively being relegated to second-class citizens on the internet.”
Even Tor’s own documentation acknowledges the problem. Websites interpret the combined traffic of exit relays as suspicious and react with CAPTCHAs, temporary blocks, or warnings about supposedly infected traffic. None of this reflects what the individual user has actually done.
The people who rely most on Tor are journalists working under hostile governments, dissidents, and victims of domestic violence who want to communicate without being tracked. Anonymous communication is a lifeline for people whose internet access is controlled by states that would harm them if they used it freely. However, CAPTCHA systems treat them the same as automated botnets.
Fraud Defense takes this even further. Google’s requirements page specifies exactly which hardware is qualified for the new QR code checks. Android phones require Google Play Services version 25.41.30 or later.
This requirement excludes any Android device that has been de-Googled. GrapheneOS, the security-hardened Android fork used by privacy enthusiasts, cannot pass the Play Integrity checks required by Fraud Defense. The same applies to LineageOS, CalyxOS, and any custom ROM that removes Google’s proprietary software layer.
Firefox for Android doesn’t even appear on Google’s list of supported browsers. Mozilla’s stance on device attestation was clearly stated back in 2023 and hasn’t changed. Users of the most privacy-friendly major mobile browser are excluded from verified access by default.
iOS users, on the other hand, pass the test without any problems, without having to install any Google software. If the requirement were truly for security purposes, Apple’s approach already proves that device attestation works even without Google’s proprietary stack. The fact that Android users specifically need Google Play Services shows what this is really about.
The hierarchy
The system that Google has built creates an access hierarchy for the web – and it is worth clearly stating who stands where.
At the top of the list are users logged into Google accounts, using Chrome, and browsing via a private home IP address. They almost never see CAPTCHAs. Below them are ordinary users who occasionally have to solve puzzles and see normal image grids. Below that are VPN users, who are subject to constant checks because their shared IP addresses have been permanently flagged.
Users report that multiple CAPTCHAs per session are now standard. At the bottom of the list are people who use Tor, have de-Googled smartphones, run Firefox with anti-fingerprinting settings, or use browsers that reject tracking cookies.
For these users, the experience ranges from endless CAPTCHA loops to complete account suspensions. Fraud Defense transforms this into a complete exclusion from websites that use the system.
Privacy is penalized, and the disclosure of personal data is rewarded with seamless access. The old system punished privacy-conscious users with more difficult puzzles. Fraud Defense can now completely block them.
The part of the surveillance that Google doesn’t talk about
Successful fraud defense checks send a signal to Google: This certified device visited this website at this time. A device with a stable hardware identity generates a persistent identifier that survives session boundaries, browser switches, and private browsing modes. The company that determines which hardware is legitimate simultaneously collects a continuous log of which websites this hardware visits on the open web.
This is in addition to the data collection that reCAPTCHA already carried out. The French data protection authority CNIL found that reCAPTCHA collects IP addresses, cookies that Google had placed on the device in the past six months, and a list of browser plugins – and that this data is used for purposes beyond purely security-related ones.
Google’s own terms of service inform companies using reCAPTCHA that the system collects hardware and software information and transmits it to Google for analysis – and that it is their responsibility to inform users about this and obtain their consent.
reCAPTCHA also sets persistent cookies that enable cross-site tracking. According to the ePrivacy Directive and the GDPR, this requires explicit prior consent. If a user rejects cookies, the reCAPTCHA script should not be loaded – which, however, destroys the functionality of forms on websites that use it. Users are forced to trade privacy for access – a consent mechanism that does not meet the GDPR requirement of freely given consent.
The QR code mechanism adds hardware-based device identification to all of this. The system that verifies you are a human simultaneously verifies your device, your location, and your identity – for an advertising company.
The bot problem that Fraud Defense doesn’t solve
Bot operators can simply point a camera at the screen to scan the QR code. This is trivial automation using off-the-shelf hardware. An Android phone that meets Play Integrity requirements costs around $30. For professional bot farms that buy devices in bulk, this is a negligible expense.
The people Fraud Defense effectively excludes are privacy-conscious users, owners of smartphones that have been de-Googled, Tor users, and people living in repressive states. These are precisely the groups least likely to be botnet operators. The actual bot operators simply bear the additional costs and carry on.
There’s another problem, unrelated to bots. Security experts warn that users can barely distinguish between legitimate Google CAPTCHA QR codes and phishing QR codes. The system trains people to reflexively scan codes to access websites. QR code phishing attacks had already more than doubled by the beginning of 2026. Google has created a system that facilitates phishing while failing to stop the bots it’s supposed to combat.
Europe has known this for a long time.
The CNIL ruled that reCAPTCHA allows Google to perform analyses that go beyond simply ensuring authentication and imposed fines on companies that used it without proper consent. The Bavarian State Office for Data Protection Supervision found that Google’s lack of transparency regarding what data reCAPTCHA actually collects makes data protection compliance virtually impossible, because website operators cannot inform users about data processing activities they themselves do not fully understand.
Data transfers to US servers conflict with the Schrems II ruling. Several European authorities in France, Austria, and Bavaria have already taken action against reCAPTCHA implementations.
Google’s response, announced in April 2026, was to formally classify itself as a data processor, which was intended to give organizations nominally more control over user data. However, the data continues to flow through Google’s infrastructure. Website operators now bear the GDPR risk for a system whose data practices they cannot fully verify. Google shifted the legal risk to its customers—without changing the actual data pipeline.
The alternatives that nobody uses
Cloudflare Turnstile offers invisible verification without device attestation and without Google dependency. It uses private access tokens and works with device manufacturers to validate devices without collecting or storing the data itself. It’s free.
Proof-of-Work systems like Friendly Captcha or ALTCHA present cryptographic challenges where computational costs scale with volume. A single human pays a negligible price. Bot farms with thousands of concurrent sessions, on the other hand, face exponentially increasing computational costs. No hardware identifier is transmitted, and no certification authority decides who receives access.
These systems prove that you are human without requiring you or your device to identify yourself to an advertising company. The difference to fraud defense is fundamental.
The adoption of such alternatives remains slow – for obvious reasons. reCAPTCHA controls roughly 85 percent of the CAPTCHA market and is embedded on more than five million websites. Web developers continue to use reCAPTCHA because it’s the standard, because it integrates seamlessly into Google’s advertising, analytics, and cloud ecosystem, and because switching seems risky – even if alternatives are technically and legally superior.
The pattern
AMP controlled content distribution, Privacy Sandbox controlled ad targeting, and Fraud Defense now controls who even gets access to the web. All these products are expanding Google’s role as gatekeeper over ever larger parts of the fundamental internet infrastructure.
Vivaldi’s warning from 2023 has aged remarkably well. Should attestation become the standard, then “any browser that doesn’t implement this would no longer be considered trustworthy, and any website using this API could reject users of such browsers.”
Google could require websites using Google Ads to implement fraud defense – and any browser or operating system that is not compliant would be effectively finished.
The web is splitting into certified and uncertified devices. Privacy-conscious users are being relegated to a second class, where services disappear simply because they refused to run proprietary software from an advertising corporation.
The real question was never whether the web needs bot protection. Of course it does. The real question is whether bot protection truly requires handing over a persistent hardware identifier for every internet user in the world to a single company – when alternatives already exist that don’t require this.